
PROJECT MANAGEMENT (boiled down to its practical) ESSENTIALS
Project management: Some love it. Some hate it. Some overkill it. Some ignore it.
Here's my take:
Ideally, the goal is to do that bare minimum of project management which actually enables one to get something done.
I define the bare minimum of project management as making clear:
What will be done?
How much effort will it take?
How long will it take to put in this effort?
The only thing worse than too much project management - is the chaos resulting from none at all.
The challenge is to develop "good" software within budget and on time without excessive paddling or "analysis paralysis".

WHAT WILL BE DONE?
The most important thing to make clear is what the users are most likely to want - that they are NOT getting - in this phase of the project.
- "Project Limitations" are the easiest way to set the "Project Scope".
- When minor changes to the code's functionality don't result in major changes to the code - those changes are said to be within the "Project Scope".
HOW MUCH EFFORT WILL IT TAKE?
The EFFORT to do a project is a an estimate of the full-time hours the project will take to do, and includes normal full time work habits such as an occasional coffee break, etc.
Unless the types of projects done are very limited, no one estimates software projects perfectly all the time.
- A few good projects and you'll tend to underestimate the next few projects.
- Get burned a few times and you'll start overestimating instead.
- I've been estimating and tracking projects for over 25 years, and I still go through this cycle
- I have found that a group of (2-3) people estimating each feature of a features list (or work breakdown list) is useful. Everyone's estimates are usually close, but when someone is way off from the others - either they see something the others don't, or they misunderstand the scope of the feature.
- Some items on a work breakdown list will turn out underestimated, and others overestimated. Usually however, the work breakdown list nets out to a total accurate estimate for the project.
- The work breakdown list represents "buckets of estimated effort" for various items. In order to avoid wasting time over analyzing and over planning (decision making with some degree of uncertainty is normal when laying out projects), the work breakdown does not have to be the same as the development timeline. Once you get into it, that timeline might sequence out differently (e.g. implementing functionality across modules rather than developing it one module at a time - or vice versa). The important thing is that total time spent implementing functionality nets out to the total time predicted for the project - and that the committed end date is met.
Coding Effort Multipliers
Some typical effort multipliers based on post project regressions from other jobs:
Application Domain |
|||
|---|---|---|---|
Application, |
You know the ins and outs of what the code is used for |
You've never worked with code that does this stuff |
|
You know the programming language, operating system, etc. |
If you know the application and have worked in the application domain, your estimates should be pretty close. (+0%) |
If you know the language & operating system, but haven't worked in the domain, it will be harder to anticipate the "scope" of the project.
(+50-100%) |
|
The programming language, operating system, application, or class library (etc.)
are new to you |
If you know the domain, but not the application or the language, you'll have to add some padding to come up to speed. (+20-30%) |
Not knowing the domain nor the application makes it difficult to estimate the project. (+300%) |
|
Post Coding Estimate Percentages
I've tracked the data on most of my projects over the years. For the type of work I've done, here's what the later steps wind up being for projects bigger than a few weeks of effort:
Debug: |
+20% of the coding effort for "Glasshouse" or purely computer applications +30% of the coding effort if machinery, instrumentation, vision, robotics, etc., and interfacing/coordination is involved Testing and debug effort depend on staffing, time to compete in the marketplace, and the margin for error (e.g. shrink wrapped software and fab recipe selection being far more sensitive to error than say - internal reports). Testing and debug effort goes up as these dimensions narrow. |
Documentation, (limited) user training: |
+5 to 10% of the coding effort |
Overhead (administration, meetings, status reporting): |
+15 to 20% of the coding effort (in a company larger than a few dozen people) |
This is not only for your own estimates, but also for outside contractors who claim they can complete a (e.g.) 6 month coding effort with 2 weeks of onsite installation and debug. Chances are that, before you're done, it will wind up being around 6 weeks of debug (= 20-30% of the 6 month development effort) if the project is to be successful.
HOW LONG WILL IT TAKE TO PUT IN THIS EFFORT?
"More software projects have gone awry for lack of calendar time than for all other causes combined." -The Mythical Man Month
EFFORT is Not TIMESPAN
The EFFORT to do a project is a an estimate of the full-time hours the project will take to do, and includes normal full time work habits such as an occasional coffee break, etc.
- The customer's cost to do the project is based on the EFFORT.
TIMESPAN is how long it takes to put in these given number of hours (of EFFORT) on a project.
- i.e., Estimate the EFFORT as the full time timespan it will take to develop the code - assuming no other concurrent maintenance or development responsibilities. Then simply divide this number by your availability (e.g. if you can devote 40% of your work week to the project, divide the EFFORT estimate by 0.4 to get the project TIMESPAN).
EFFORT and TIMESPAN are frequently confused.
The most frequent problem in scheduling projects is that your availability to develop code can be difficult to predict when unpredictable line maintenance responsibilities are also involved.
- In many environments, unscheduled maintenance and support activities pre-empt an effort for a few hours to a few days. Splitting development time between projects also extends a TIMESPAN for completion, but does not effect an individual project's EFFORT.
Solution:
Track your actual average "availability" for development work over a several month timespan.
While you cannot say how much time you'll devote to the project tomorrow - you CAN say (on the average) how much time you'll be able to devote to the project over a month.Use this (long term average availability) to predict how long it will take to do N weeks worth of (full time) effort.
- e.g.: For a 70% availability, a 10 week (full time) development EFFORT will take a 10 week / 0.7 availability = 14.3 week TIMESPAN.
Estimate the full time EFFORT, and then the TIMESPAN to do the job.
The purpose of a work breakdown and schedule is to accurately predict the future (i.e., when the project will be done and at what cost).
Some might not like this prediction. Do NOT shave down an EFFORT estimate purely to meet a delivery date to an end user.
- If you make this mistake (which is a VERY common corporate scenario), chances are you won't make the committed due date anyway (which is often very, very important). Overtime and weekends are reserved for addressing unforeseen issues arising out of left field. Depending upon overtime and weekends for normal project development in order to make a deadline is a recipe for burn out, mistakes - and ultimately: missed deadlines.
- Putting more people on the project (to work concurrently) to reduce a timespan ONLY works if the project can be partitioned.
- You CAN shave down functionality/deliverables - to reduce the effort - in order to meet a date; but then the reduced project scope must be clear. It's a tradeoff.
TRACKING PROGRESS
80% of the functionality will be completed within the first half of the project.
It will take the other half of the project to get that last 20% correct.
This is how it should be. Keeping in mind that experience tells you which details the big picture turns on, on most projects you want to get the more fluid breadth-first top-down broad functionality established before filling in the lower level details. This has an effect on "Project Tracking":
It is more accurate to gauge project progress based on the analytical:
Project % Complete = (hours spent) / (total hours estimated)
rather than the more subjective:
Project % Complete = (functionality developed) / (total functionality needed)
PARTIONING CODE DEVELOPMENT
If one woman can have have a baby in nine months, then why can't nine women have a baby in one month?
... because this is is an example of an "unpartitionable" task.
Partitioning new code development among a team of programmers is rarely discussed in software engineering literature, yet it is often critical.
- Code is often not easily "partitionable" at the level of developing a group of interdependent, tightly coupled routines and modules.
- Adding modules to a tightly coupled system is like doing an organ transplant.
- Determining what the "groups" of loosely coupled routines and modules are - is essential to coming up with a software design that can be partitioned out among developers.
- Adding modules to a loosely coupled system is like snapping in lego bricks.
- Once again: putting more people on the project (to work concurrently) to reduce a timespan ONLY works if the project can be cleanly partitioned.
- "Adding programmers to a late software project only makes it later." - The Mythical Man Month
Good Partitioning |
One person codes, another person:
|
|---|---|
Mediocre Partitioning |
One person codes, another debugs |
Bad Partitioning |
Multiple programmers, with very different views of what constitutes good code, maintaining the same modules (see: writing joke). |
PEOPLEWARE
"...it's such a large project... There will be so many people involved, each with authority, each wanting to exercise it in one way or another".
— Ayn Rand, "The Fountainhead"
Getting people to agree on what "good software" is goes a long way towards being able to cohesively work together.
- Simplifiers vs. Optimizers:
- An optimizer looks for the very best solution - even if the extra complexity increases the odds of unexpected problems.
- People can follow simple systems better than complicated ones. If the cost of failure is high, simple tasks are the best.
- Team playing and leadership are all about getting past the cognitive dissonance of other's (often less than perfect) programming styles and design approaches - in order to get the job done in a finite timeframe.
Comfort zone and workflow are everything.
- For lots of very good reasons (like working quickly and efficiently, having a "workflow", knowledge is power, etc.), people like working deep in their comfort zone and heavily resist being forced out of it.
- The major cause of low programmer morale is when the person responsible for making it work does not buy into how it is to be done.
Programmer Skills Hierarchy:
The real world of developing something useful and maintainable, delivered on time and within budget, necessitates a skills hierarchy that goes like this:
Good |
Knows a programming language, and can develop code that works.
|
|---|---|
Better |
Writes code that others can understand. Codes for simplicity (rather than with terseness, speed, low memory usage).
|
Best |
Can issue effort and time span estimates - and then develop code within them.
|
WHAT IS "GOOD" SOFTWARE?
There are many ways in which reasonable people can disagree, and whole books have been written which encompass the following points. These are not "universal truths", but my own boiled down generalizations. They stem from reflecting upon the particular work environments I've have been in.
It should work, be used and useful.
- Meeting schedules, budgets and formal requirements with software that end users consider a millstone around their necks - is not a good thing.
- It is important to flush out screen GUIs and identify awkward functionality with the end users, as part of alpha or beta testing.
- The "scope" of a project is defined as that where likely minor changes do not take a major rework of the design.
In the end, the average customer doesn't care if an application is developed in GWBASIC, Visual Basic, C#, or Assembly for that matter, as long as it looks good, runs good, and works well.
- Among modern programming languages, debugging capability is much more important than language particulars.
Design and Code should strive for ease of understanding.
Whether other programmers can learn, debug and enhance code is MORE important than performance, reuse, generality, being terse,...
- Cpu speed and memory are cheap. Programmer time is expensive.
- Software should have right degree of "generalization" for the problem and budget at hand. The less the programmer understands the application domain or the likely paths of change - the
more generalized (and complicated) they write the software (see programming joke).
- Reducing a chaotic set of requirements to simple categories, and then coming up with an easily understood, obvious (and by necessity: limited) design - takes far more up front thought and negotiation than an overly generalized solution.
- As in all writing: the more intelligent the writer, the easier they are to understand (Feynman's lectures come to mind). The ultimate test of code maintainability is whether it lives on (to be used, useful, and enhanced) well past its originators.
PROJECT MANAGEMENT METHODOLOGY
I realize that "Waterfall", is considered dated, old school, and otherwise antiquated... but anyone who does anything (even when it is broken up into smaller iterative chunks under whatever software development process) still follows some variation of basic iterative Waterfall Process steps/stages/phases:
- Feasibility: An optional phase to figure out essential unknowns
- e.g: Should I eat breakfast?
- Analysis: What's the problem and how can we solve it? What are the rough costs of different approaches?
- e.g. What's at hand in the house for breakfast?
- Design: How we will solve the problem and what will it cost (effort, timespan)?
Scope/Limitations: What we won't do in this pass that the users are most likely to want.
- e.g. Should I go to the store, or settle for toast?
- Coding
- e.g. I'll cook some toast.
- Test: Is desk testing, alpha (or the programmer is present) testing, or beta (or the programmer isn't right there) testing
- e.g. I burned the toast. Let me try again.
- Maintain: As users come up with better ideas for this or that.
- e.g. Let me pickup a different flavor of jelly on the way home tomorrow, so we have it for the next batch of toast.
LARGE PROJECT ITERATIVE METHODOLOGY
Small projects, or projects with fairly straight forward requirements don't have to be iterated much, but in general I use the following process to ferret out requirements on larger projects in which the users won't know what they really want until they actually see and use the software (which is frequently the case - like test driving a car before buying it).
- Prototype breadth-first
- If you can write code as fast as you can write up a specification, then prototype the software user interfaces (along with limited functionality, or stubs denoting future functionality). It will be easier for end users to understand.
- The BIGGEST thing experience teaches are which details to concentrate on up front - that the project will later turn on.
- Figure out the one or two items that form the "core" of the system, and start with them.
- Iterate the breadth-first prototype (user feedback→revise→user feedback→revise.).
- Break up larger projects up into their components (e.g. inventory, payments, sales, shipping, ...). Advance an initial "straw-man" at what these pieces are and reorganize them as needed. Two or three iterations of the major (stubbed out) screens for each major component usually suffice.
- Go into depth only after the iterations have converged/stabilized (preferably across the whole project) - on how the big picture goes together. At this point revisit EFFORT and TIMESPAN estimates.
- Requirements are being converged upon if the users want less and less revision with each iteration. The converse (i.e., the users want more and more with each iteration) is indicative of an unstable project whose odds of success are low.
- Don't spend time making nice, neat code generalizations until you have a fairly good idea of how the whole system lays out. Only then can its data and functionality be
efficiently
categorized.
- The disadvantage of an iterative process is that (just like the human body) sometimes useless appendages creep in during software evolution (e.g., unused or redundant data structure elements, table columns - which don't always get cleaned up), as the "real" requirements surface. This disadvantage pales in comparison with an iteration and software evolution process that holds the bottom line advantage of "hitting the nail on the head" for the end user.
- Software developers sometimes get more hung up in how software is constructed and projects are managed - than in the functionality they are delivering to the end user.
- The disadvantage of an iterative process is that (just like the human body) sometimes useless appendages creep in during software evolution (e.g., unused or redundant data structure elements, table columns - which don't always get cleaned up), as the "real" requirements surface. This disadvantage pales in comparison with an iteration and software evolution process that holds the bottom line advantage of "hitting the nail on the head" for the end user.
- Despite any amount of up front work, it is always VERY important to flush out screen GUIs and identify awkward functionality with the end users toward the end of development - as part of alpha or beta testing.
- When software has been developed overseas, on too tight of a fixed budget, or with too formal a process - this step is often skipped. There is no getting around it. You can tell if it's been skipped from the user frustration.
For new large system development
(as opposed to self evident enhancements to an existing system)
I do not:
- Write up a full set of requirements.
- Review this document up with the users. Revise as appropriate. Get a sign off.
- Code, test, install, train.
I have never seen this approach work.
- In the best case, it only leads to later rounds of corrective change and enhancement - that should have been iteratively flushed out during the initial development.
- When developing new software, the users won't know it until they see it. Reviewing an iterative series of working software prototypes works much, much better than reviewing a document.
SMALL PROJECT METHODOLOGY
This is the approach I used to sort out an inhouse manufacturing context with a lot of competing internal priorities. Other contexts might call for other approaches.
Click on the image thumbnail below for a bigger picture.
Initial Project Estimates, |
Quick estimates, accurate to within some margin, are usually better for sorting a list of competing priorities than accurate ones which take 30% of the total project time to pin down. If the delivery date is not critical (i.e., plant production and customer commits are not depending upon it), then don't get lost in "analysis paralysis". |
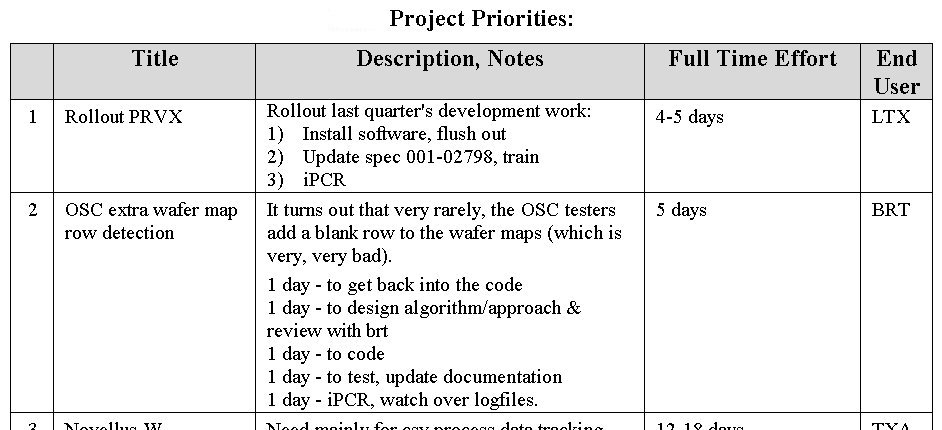 |
||
Estimated vs. Actual Project Efforts |
Keep the hours tracking simple, easy and quick. Unless the customer is paying by the hour, track to the nearest 15-30 minutes per day. |
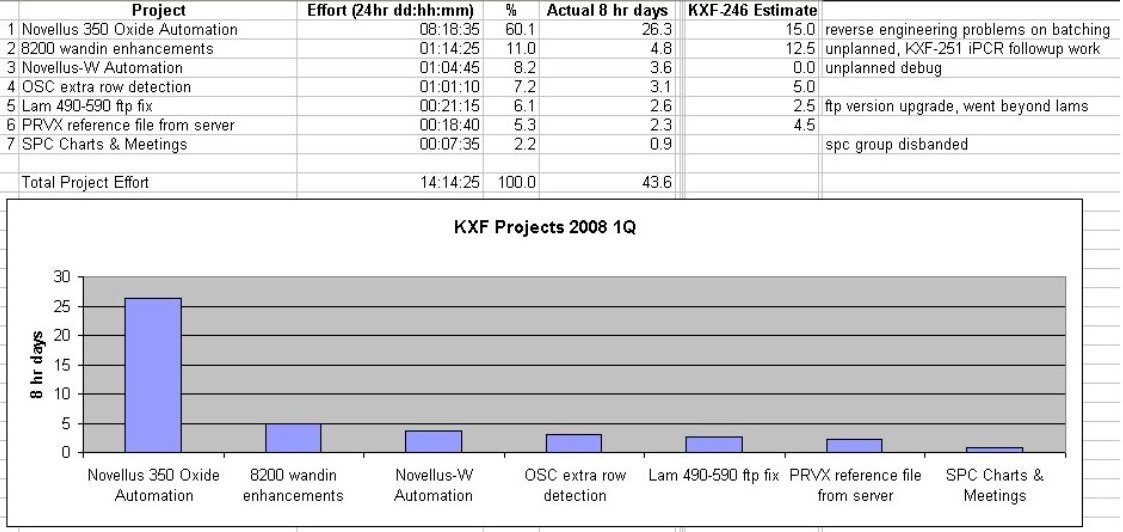 |
||
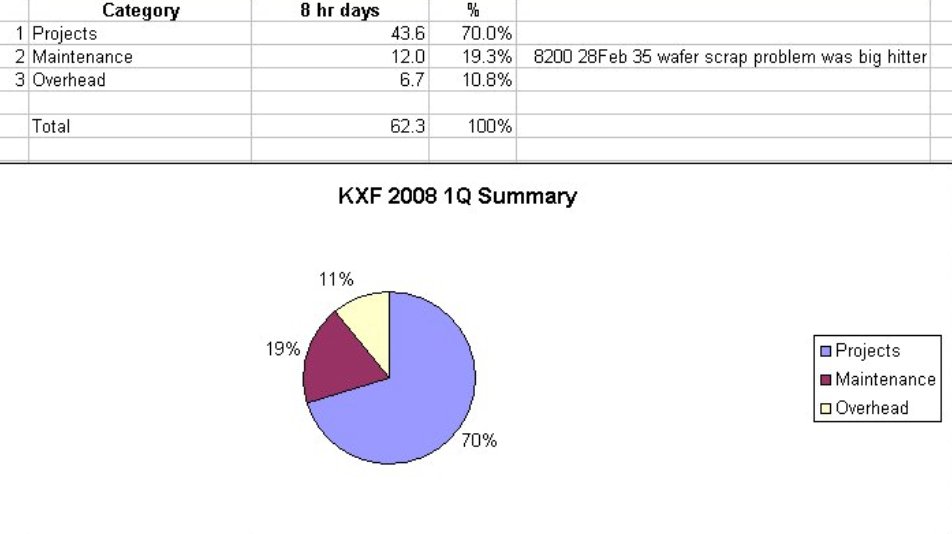
Maintenance, Overhead, Project Availability Summary |
Using an Excel spreadsheet, it takes me about 8 hours to sum up and issue a memo on a quarter's worth of work. The purpose of this is to (i) get the "availability" for future project development, and (ii) see if any items spent on maintenance, Pareto out above the noise and should be prioritized as "root cause fix" type projects. |
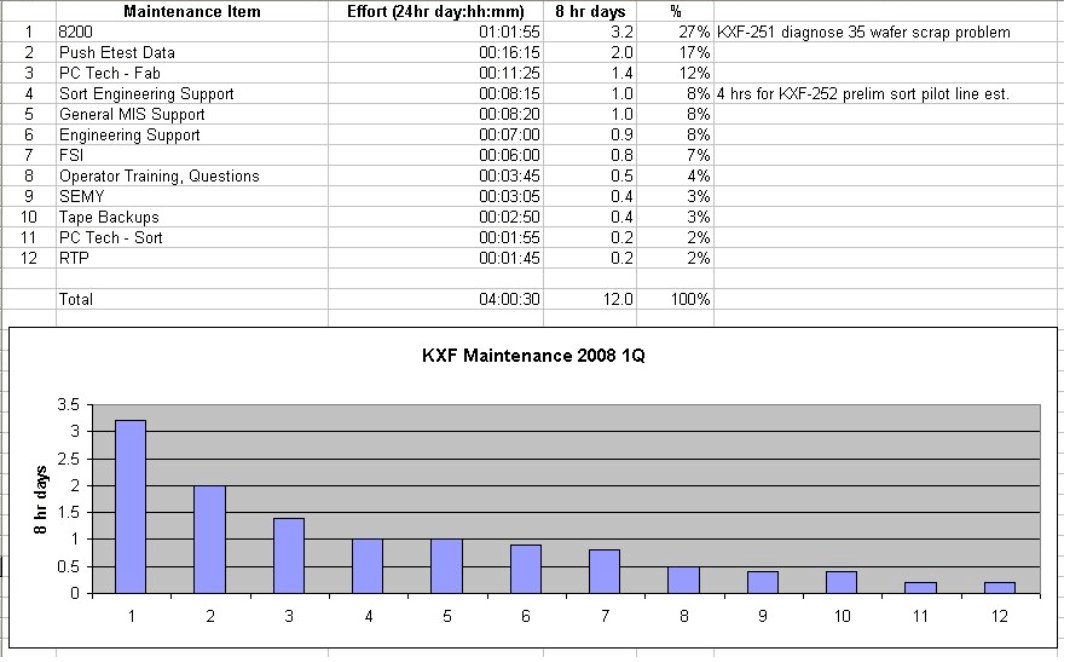 |
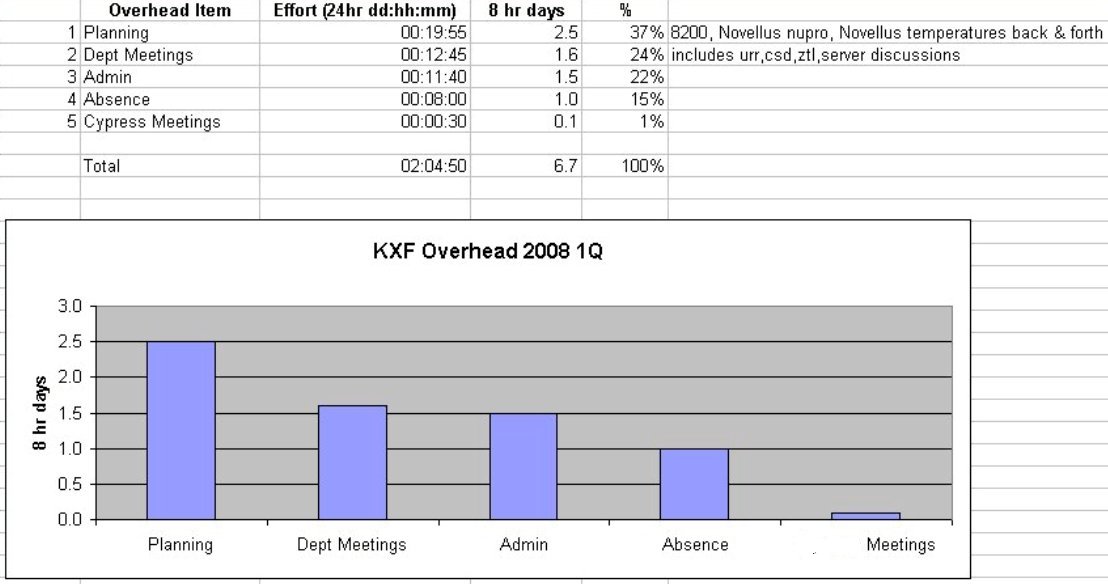 |
 |
Favorite Workplace Project Management Guide
Final observation ...
The more your computer training, the more abstractly you approach problems
An engineer writes a program to solve a problem.
Con: Their code tends to be a collection of point solutions. They don't generalize when they should.
A programmer invents a language, class library, or pre compiler tools to solve a problem.
They sometimes get more hung up in how code is constructed - than in the end user functionality they are delivering.
A computer scientist writes a specification for a language to solve a problem.
If they're witty they write books and lecture, or become software methodologists.
A PhD writes a grammar for a specification for a language to solve a problem.
Abstraction being what it is, a PhD Computer Scientist can be compared to a theologian who knows some math.
Copyright ©2014 by Ken Freed. All rights reserved.